什么是索引下推 (Index Condition Pushdown)?
一个去图书馆找书的比喻
想象一下,数据库就是一个巨大的图书馆,而您是找书的人。
- MySQL服务层 (Server Layer):就是您自己。
- 存储引擎层 (Storage Engine Layer, 如InnoDB):就是图书馆里专业的图书管理员,他熟悉所有书架和索引卡片。
- 数据表:就是书架上的所有书。
- 索引:就是图书馆的索引卡片柜,它能帮您快速定位到书的位置。
假设您有一个复合索引,它由“作者”和“性别”两部分组成。
现在,您的任务是找到所有“作者为张三”,并且“性别男性”的书。
没有索引下推(MySQL 5.6之前)
在没有索引下推的旧模式下,流程是这样的:
- 您(服务层)对管理员(存储引擎)说:“请把所有作者是‘张三’的书的位置告诉我。”
- 管理员(存储引擎) 使用索引卡片(索引),非常快地找到了所有作者是“张三”的书的位置,并把这些位置信息(比如100个位置)全部告诉了您。
- 您(服务层) 拿到这100个位置列表后,需要亲自跑100趟书架:
- 第一趟:跑到第一个位置,拿到书,检查这本书的作者性别是不是“男性”。不是,放回去。
- 第二趟:跑到第二个位置,拿到书,检查性别。不是,放回去。
- …
- 第五十趟:跑到第五十个位置,拿到书,检查性别。**是“男性”!**太好了,把这本书放到您的手推车里。
- …继续跑完剩下的50趟。
问题所在:您和管理员之间进行了大量的数据交互(100次位置信息传递),并且您自己做了很多无效的“回书架取书再检查”的操作。很多书您明明拿起来一看就知道不符合第二个条件,但还是得先拿起来再说。
有了索引下推(MySQL 5.6及之后)
现在,流程变得智能多了:
- 您(服务层)对管理员(存储引擎)说:“请帮我找所有作者是‘张三’的书,并且在你找到这些书的索引卡片时,顺便帮我检查一下卡片上记录的性别是不是‘男性’。只把那些两个条件都满足的书的位置告诉我。”
- 管理员(存储引擎) 使用索引卡片,找到了第一张作者是“张三”的卡片。他看了一眼卡片上的第二个信息,发现性别是“女性”,不符合要求,直接跳过。
- 他继续找,又找到一张作者是“张三”的卡片,看到是“女性”,不符合,继续跳过。
- …
- 他找到一张作者是“张三”的卡片,看到首字母是“女性”,两个条件都满足! 于是,他把这个位置记录下来。
- 最终,管理员只把那些真正符合所有条件的位置信息(比如只有5个位置)告诉了您。
- 您(服务层) 只需要跑5趟书架,拿到的每一本书都是您最终想要的。
这就是“索引下推”:您把“检查性别”这个过滤条件,“下推”给了离数据(索引卡片)最近的管理员去执行。
索引下推 (Index Condition Pushdown, ICP) 的工作原理和优势
下面,我们将一步步搭建场景、编写代码,并通过 EXPLAIN 来分析其效果。
概念回顾:图书馆借书的比喻 📚
在解释代码前,我们用一个比喻快速回顾下 ICP 是什么:
- 没有 ICP 的情况 ❌: 你告诉图书管理员:“请把 计算机科学书架上 的所有书都推过来,我自己来找作者名是 ‘张’ 开头的。”
- 过程:管理员把整个书架(满足第一个索引条件
city)的书都搬到你面前,你再一本本翻看(Server 层进行第二次过滤name)。这会搬运很多你不需要的书。
- 过程:管理员把整个书架(满足第一个索引条件
- 有 ICP 的情况 ✅: 你告诉图书管理员:“请去 计算机科学书架,只把作者名是 ‘张’ 开头的书拿给我。”
- 过程:管理员在书架旁就完成了筛选(存储引擎层直接过滤
name),只把精准匹配的书交给你。这大大减少了无效的搬运工作。
- 过程:管理员在书架旁就完成了筛选(存储引擎层直接过滤
在数据库中,“搬运工作” 就是存储引擎(如 InnoDB)将数据行返回给 MySQL Server 层的过程。ICP 的核心就是将本应在 Server 层做的过滤条件,“下推” 到存储引擎层,利用索引信息直接完成过滤,从而减少不必要的数据读取(回表)和传输。
真实案例构造:用户管理系统查询 👨💻
假设我们有一个用户表,需要频繁地根据 城市 和 姓名 进行查询。
1. 创建表和索引
我们创建一个 users 表,并建立一个由 city 和 name 组成的复合索引。
1 | CREATE TABLE `users` ( |
2. 插入测试数据
我们插入一些数据,特意让同一个城市下有多个不同姓氏的用户,以便观察过滤效果。
1 | INSERT INTO `users` (`city`, `name`, `age`, `email`) VALUES |
代码层面演示与分析
我们的目标查询是:查找所有在北京,且姓 ‘张’ 的用户。
SQL
1 | SELECT * FROM users WHERE city = '北京' AND name LIKE '张%'; |
这个查询中,city = '北京' 可以精确匹配复合索引 idx_city_name 的第一部分。name LIKE '张%' 是对索引第二部分的范围查询。这是触发 ICP 的典型场景。
场景一:手动关闭 ICP (模拟旧版 MySQL)
我们先关闭 ICP 功能,看看数据库是如何执行查询的。
1 | -- 关闭 ICP 功能 |
你会得到类似下面这样的 EXPLAIN 结果 (核心列):
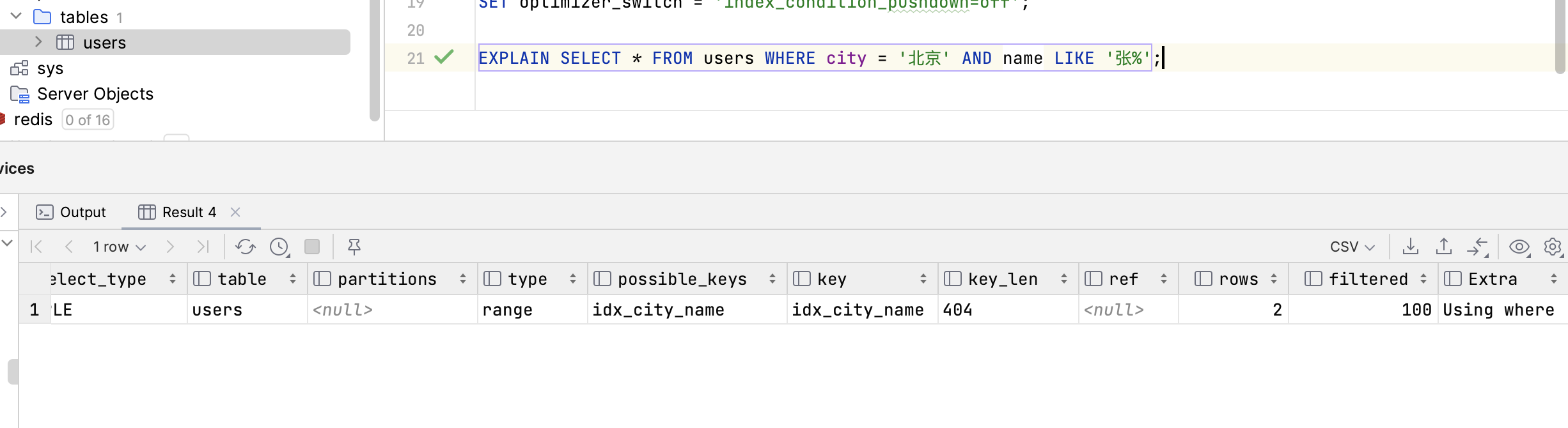
结果分析 (无 ICP):
key: idx_city_name: 优化器决定使用idx_city_name索引。type: range: 它通过索引找到了city = '北京'的所有记录。根据我们的数据,这包括 ‘张三’,’李四’, ‘张伟’ 这三条。Extra: Using where: 这是关键!它表示存储引擎(InnoDB)将这三条记录的完整数据全部从主键索引中读取出来(这个过程叫“回表”),然后返回给 MySQL Server 层。Server 层再应用WHERE name LIKE '张%'这个条件,把 ‘李四’ 这条记录过滤掉。- 工作流程: 索引定位 (
city='北京') -> 回表获取3条完整数据 -> Server层过滤 (name LIKE '张%') -> 返回2条结果。其中,李四这条记录被无效地读取和传输了。
场景二:开启 ICP (默认行为)
现在我们重新开启 ICP(这也是 MySQL 5.6+ 的默认行为),再看一次执行计划。
1 | -- 开启 ICP 功能 |
EXPLAIN 结果会发生关键变化:

结果分析 (有 ICP):
key: idx_city_name: 同样使用了idx_city_name索引。Extra: Using index condition: 这是最重要的变化!这个标志告诉我们,索引下推已经生效。- 工作流程:
- 存储引擎通过索引找到
city = '北京'的记录。 - 在不回表的情况下,它继续在索引内部检查
name字段是否满足LIKE '张%'的条件。 - 它发现只有 ‘张三’ 和 ‘张伟’ 满足,’李四’ 不满足。
- 因此,存储引擎只对 ‘张三’ 和 ‘张伟’ 这两条记录进行回表操作,获取完整数据,然后返回给 Server 层。
- 存储引擎通过索引找到
- 效率提升:
李四这条记录从未被完整读取,避免了一次无效的回表 I/O 和一次无效的数据传输。rows预估值也从 3 降到了 2,更精确
总结与优势
通过上面的真实案例和代码演示,我们可以清晰地看到 ICP 的价值:
- 减少回表次数: 这是最核心的优势。存储引擎层直接利用索引过滤掉了大量不满足条件的记录,避免了对这些记录进行昂贵的回表操作。
- 减少 I/O 操作: 由于回表次数减少,磁盘 I/O 自然也随之下降。
- 降低数据传输: 存储引擎与 Server 层之间传输的数据量变少,节省了 CPU 和网络资源。
总而言之,索引下推是一个非常智能的优化,它充分利用了存储引擎的能力,大大提升了特定查询场景下的数据库性能。