了解LangChain、LangGraph、Deep Agent 1. LangChain:AI 开发的“零件箱” LangChain 最初是为了解决“如何让 LLM 调用工具”而生的。它提供了大量的 Prompt、Retriever、Tool。
2. LangGraph:给 AI 接上“精密齿轮” 为了解决 LangChain 线性逻辑的死板,LangGraph 诞生了。它把 AI 的思考过程看作一个有向图。
3. Deep Agent:2026 年的“超级智能体” 这是 LangChain 官方最新推出的高级框架,它是基于 LangGraph 构建的。它的灵感来源于 Devin 或 Claude Code 这种“深度”Agent。
它多做了什么?
自主规划:内置了 write_todos 这种规划工具,AI 会先列计划再干活。
虚拟文件系统:它不再只靠对话上下文,它能像人类程序员一样在虚拟磁盘上读写文件、存中间笔记。
子 Agent 生成 (Sub-agents):如果主 Agent 觉得任务太重,它会自动 spawn(派生)出一个小 Agent 去跑腿,保持主逻辑的“干净”
核心逻辑实现 将项目分为三个部分:文档加载、向量化存储、以及 LangGraph 流程编排 高效率解析 Markdown 对于知识库,建议按标题或段落切分,这样能保证 AI 拿到的答案是完整的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import osfrom langchain_text_splitters import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitterfrom langchain_google_genai import GoogleGenerativeAIEmbeddingsfrom langchain_community.vectorstores import ChromaDATA_PATH = "/Users/pt/Downloads/blog/source/_posts/mysql之索引初识篇索引机制索引分类索引使用与管理综述.md" DB_PATH = "./interview_db" def build_vector_store (): if not os.path.exists(DATA_PATH): os.makedirs(DATA_PATH) print (f"请在 {DATA_PATH} 中放入 .md 文件后再运行" ) return print ("正在加载 Markdown 文件..." ) if os.path.isdir(DATA_PATH): from langchain_community.document_loaders import DirectoryLoader loader = DirectoryLoader(DATA_PATH, glob="**/*.md" ) else : from langchain_community.document_loaders import TextLoader loader = TextLoader(DATA_PATH) raw_docs = loader.load() headers_to_split_on = [("#" , "H1" ), ("##" , "H2" ), ("###" , "H3" )] md_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on) text_splitter = RecursiveCharacterTextSplitter(chunk_size=800 , chunk_overlap=100 ) final_chunks = [] for doc in raw_docs: header_splits = md_splitter.split_text(doc.page_content) for split in header_splits: split.metadata["source" ] = doc.metadata.get("source" , "Unknown" ) final_chunks.extend(text_splitter.split_documents(header_splits)) print (f"正在向量化并存入数据库 (共 {len (final_chunks)} 个切片)..." ) embeddings = GoogleGenerativeAIEmbeddings(model="models/gemini-embedding-001" ) Chroma.from_documents( documents=final_chunks, embedding=embeddings, persist_directory=DB_PATH ) print ("向量数据库构建完成!" ) if __name__ == "__main__" : build_vector_store()
整合 LangGraph Agent 加入一个“自我检查”逻辑:如果搜到的资料和问题不相关,AI 应该承认不知道,而不是瞎编
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 from typing import TypedDict, List from langgraph.graph import StateGraph, ENDfrom langchain_google_genai import ChatGoogleGenerativeAI, GoogleGenerativeAIEmbeddingsfrom langchain_community.vectorstores import Chromaclass AgentState (TypedDict ): question: str context: str answer: str source_docs: List [str ] is_relevant: bool embeddings = GoogleGenerativeAIEmbeddings(model="models/gemini-embedding-001" ) llm = ChatGoogleGenerativeAI(model="gemini-2.5-flash" , temperature=0 ) vector_db = Chroma(persist_directory="./interview_db" , embedding_function=embeddings) def retrieve (state: AgentState ): query = state["question" ] docs = vector_db.similarity_search(query, k=3 ) context = "\n\n" .join([d.page_content for d in docs]) sources = list (set ([d.metadata.get("source" , "未知" ) for d in docs])) return {"context" : context, "source_docs" : sources} def grade_relevance (state: AgentState ): prompt = f"""评估以下检索到的资料是否能回答问题。 问题: {state['question' ]} 资料: {state['context' ]} 仅回答 'yes' 或 'no'。""" res = llm.invoke(prompt) is_relevant = "yes" in res.content.lower() return {"is_relevant" : is_relevant} def generate (state: AgentState ): if not state["is_relevant" ]: return {"answer" : "抱歉,我的面试题库中没有足够的信息回答这个问题。" } prompt = f"""你是一个高级技术面试官。请基于参考资料深度回答问题。 如果资料中包含代码块,请务必保留并解释。 参考资料: {state['context' ]} 问题: {state['question' ]} """ response = llm.invoke(prompt) answer = f"{response.content} \n\n[参考来源: {', ' .join(state['source_docs' ])} ]" return {"answer" : answer} workflow = StateGraph(AgentState) workflow.add_node("retrieve" , retrieve) workflow.add_node("grade" , grade_relevance) workflow.add_node("generate" , generate) workflow.set_entry_point("retrieve" ) workflow.add_edge("retrieve" , "grade" ) workflow.add_edge("grade" , "generate" ) workflow.add_edge("generate" , END) agent_app = workflow.compile ()
交互式对话 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from ingest import build_vector_storefrom agent import agent_appimport osos.environ["LANGCHAIN_TRACING_V2" ] = "true" os.environ["LANGCHAIN_PROJECT" ] = "Workspace 1" os.environ["LANGCHAIN_API_KEY" ] = "lsv2_pt_7b1011bf2d49c19c3b8f13c683a044_d8ae0e930b" def main (): if not os.path.exists("./interview_db" ): print ("首次运行,检测到数据库不存在,正在构建..." ) build_vector_store() print ("\n🚀 面试助手已就绪!(输入 'exit' 退出)" ) while True : user_input = input ("\n问:" ) if user_input.lower() in ["exit" , "quit" , "退出" ]: break inputs = {"question" : user_input} for output in agent_app.stream(inputs): if "generate" in output: print (f"\n答:{output['generate' ]['answer' ]} " ) if __name__ == "__main__" : main()
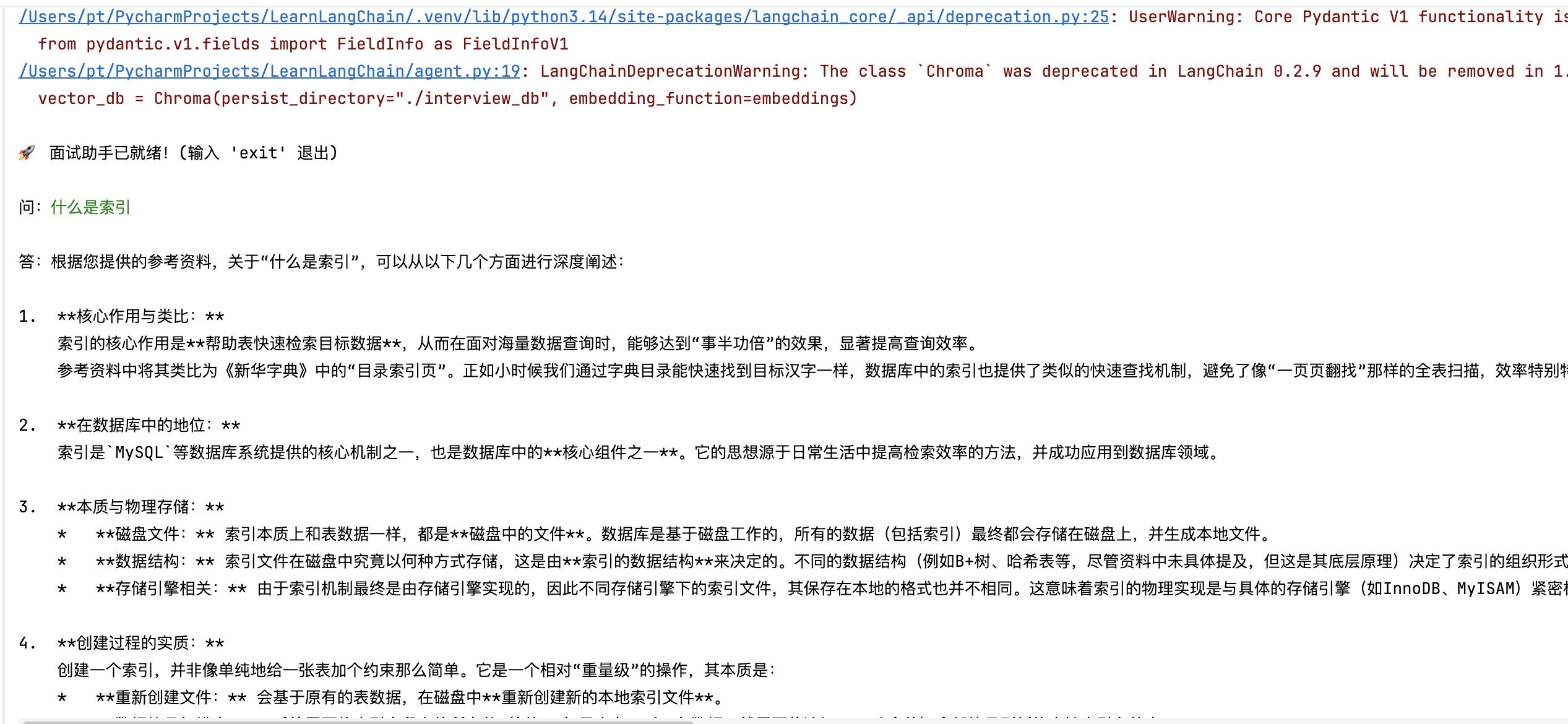
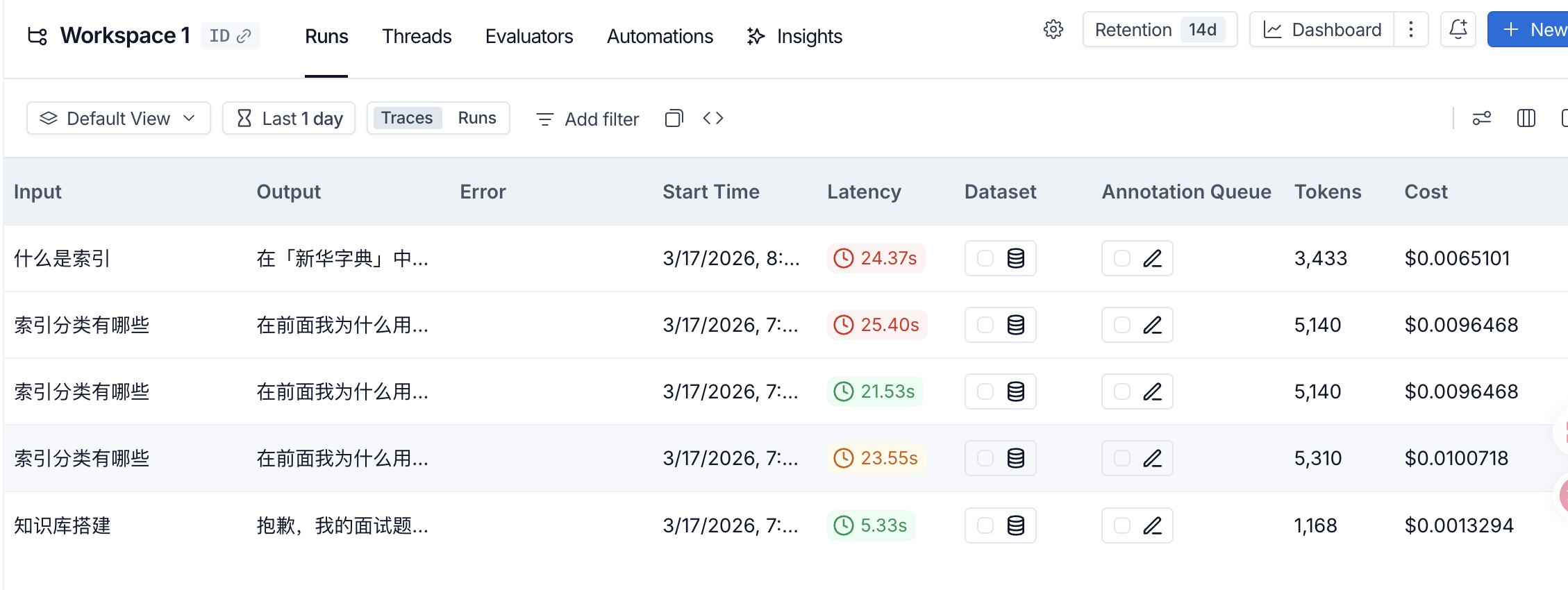
效果图